Greetings
In a previous article, I explained how we synced the WordPress website into our microservices architecture. We use AWS EKS for our deployments and managing microservices.
But what if we use a serverless architecture? Here is my attempt at the serverless solution on my serverless journey.
Note that this is about converting your own website into a serverless architecture. Always check ethicality in use.
In a previous article, I explained how we synced the WordPress website into our microservices architecture. We use AWS EKS for our deployments and managing microservices.
But what if we use a serverless architecture? Here is my attempt at the serverless solution on my serverless journey.
Note that this is about converting your own website into a serverless architecture. Always check ethicality in use.
Note: This is about the architecture, not about actual coding.
Requirement
Convert existing website into a serverless microservice.Technologies
By sticking into Nodejs and AWS I would go with the below stack.- AWS Lambda
- AWS S3
- AWS Eventbridge
- AWS RDS
- AWS API gateway
- AWS Cognito
- AWS CloudFront
- AWS Amplify
- AWS SES
- Nodejs
- JavaScript
- Axios
- Cheerio
- React
I would consider AWS Step functions in the future as one lambda is doing too many things (save in database, store images in S3, send emails). However, my AWS Step functions knowledge is not as great as today.
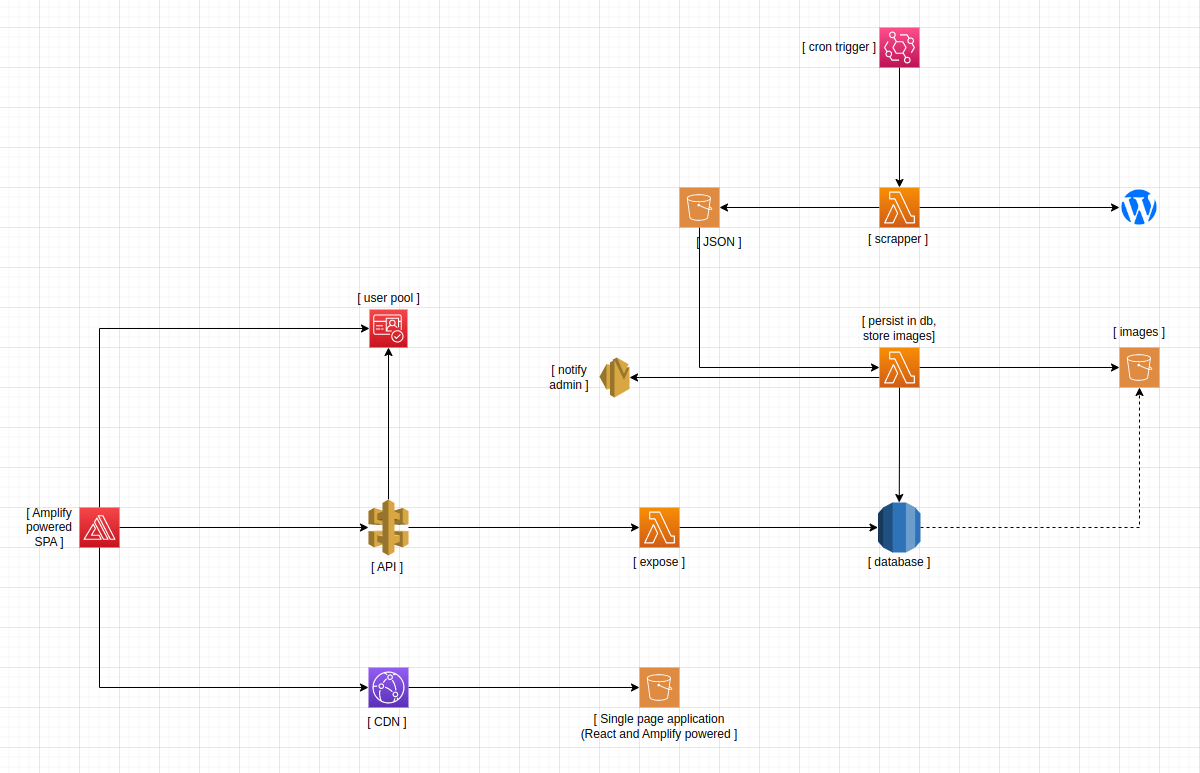
One notable decision I would take is to separate scraping and inserting the database into two lambdas. This is to make the single responsibility clear. That would make the architecture a little complex but the code is simpler.
Also, note that we will have multiple Lambdas to expose the data as rest API even though I haven't added multiple Lambdas.
That's it guys. Enjoy your serverless journey.
Architecture
Let's assume that we need to scrape new content every day. To keep both systems in sync until the old website is discarded we need to sync new content. We use Eventbridge for this purpose to execute a lambda that is responsible for scrapping the website. Once the scraping is done the results are uploaded into an S3 bucket in JSON format. Another lambda will listen to that event and insert the data into the database and any images into the S3 bucket.One notable decision I would take is to separate scraping and inserting the database into two lambdas. This is to make the single responsibility clear. That would make the architecture a little complex but the code is simpler.
Also, note that we will have multiple Lambdas to expose the data as rest API even though I haven't added multiple Lambdas.
Benefits
The serverless solution is much more elegant. It is automatically highly scalable and available due to the use of multiple managed services. It is resilient to failures and secure. The cost would be almost zero at least at the beginning.That's it guys. Enjoy your serverless journey.
Comments
Post a Comment